DeepSe...
」 DeepSeek 模型 OpenAI AI 人工智慧
AI訓練費差300倍!DeepSeek-R1只花29.4萬美元 OpenAI要1億美元起跳
中國人工智慧(AI)企業深度求索(DeepSeek)透露,開源AI模型DeepSeek-R1的訓練費用僅為29.4萬美元(約新台幣888萬元),遠低於美國同行公布的數字。路透報導,上述數據出現在由DeepSeek團隊撰寫、17日登上國際學術期刊「自然」(Nature)的論文中。這篇由DeepSeek團隊共同完成、創辦人梁文鋒擔任通訊作者的論文,介紹了開源AI模型DeepSeek-R1採用的大規模推理模型訓練方法,並稱DeepSeek-R1的訓練成本為29.4萬美元,使用了512顆輝達H800晶片。今年1月公布的DeepSeek-R1初版論文並未包含上述消息。訓練用於AI聊天機器人的大型語言模型,主要花費在用強大的晶片集群連續數週或數月處理大量文字和代碼上。儘管美國AI巨頭OpenAI未披露任何模型的具體成本,但公司首席執行官奧爾特曼(Sam Altman)曾在2023年說,基礎模型訓練花費遠超1億美元。

驚奇牛市1/上證恒生指數皆創新高 14檔陸股ETF齊飛
台股在今(2025)年飛高高,8月站穩24000點,陸港股也同步衝高,上證指數越過3800點創十年來新高,恒生指數逼近26000點創四年來高點,陸港股齊飛資金面升溫,帶動國內14檔陸股主題ETF高漲。記者根據CMoney統計資料,整理14檔陸股主題ETF近三個月股價漲幅,由復華中國5G(00877)拔頭籌,從10元初漲到21元,漲幅達92%;其次為永豐中國科技50大(00887),股價漲幅達46%,站回10元以上的雙位數。今年以來漲幅超過20%共5檔,包括富邦深100(00639)、群益深証中小(00643)、富邦中証500(00783)、元大MSCI A股(00739)、復華滬深(006207);富邦上証(006205)則是快20%。國泰中國A50(00636)、元大上證50(006206)、台新MSCI中國(00703)、中信中國高股息(00882)等也有15%以上。中信中國50(00752)股價漲幅超過10%,富邦恒生國企(00700)則快8%。值得注意的是,這14檔陸股ETF股價雖漲,但近三個月受益人數卻皆下滑數十到數千人。其中, 00882中信中國高股息基金規模近381億元居冠,受益人數超過11.4萬人;00887受益人數則近2.4萬人,00752的受益人數為2萬人,其他檔受益人數多為數千人到1萬多人。富邦投信基金經理人陳婉寧表示,陸港股歷經2021年至2023年空頭修正行情,2024年開始觸底反彈,今年走出漂亮的牛市格局,背後重要原因離不開官方持續推出的各項政策、國家隊撐盤以及科技創新的進展,不同特色的陸港股ETF也接替輪番表現。中國7月CPI年增率下降,主要受到食品價格滑落而拖累,雞蛋和豬肉供給過剩加上基期過高所致。(圖/新華社)陳婉寧告訴CTWANT記者,今年1月底DeepSeek-R1開源模型橫空出世,大幅提振市場對於中國科技發展以及AI應用普及的信心,也推升港股一度成為亞洲表現最佳市場,同時,中國不留餘力推動經濟轉型,強調科技自主決心的大趨勢下。雖然今年第一季A股整體表現遜色於港股,不過隨著中美貿易休戰、官方持續推出消費刺激及供給面改革政策,尤其是強調反內卷的指導方針,有利於改善不合理的低價競爭情況,提升整體上市企業的獲利能力。多項利多因素疊加點燃了A股強勢行情,推動上證綜合指數創下10年來新高,也拉近與港股今年以來漲幅的差距,且隨著慢牛格局確立,一般投資人信心逐漸回復,中國家庭的超額儲蓄有望投入股市,A股大盤後市展望正向。目前陸股ETF中,市值型ETF有兩檔006205及00639,分別追蹤上証180指數及深証100指數,主要持股為在A股上市的大中型市值公司,能反映滬深兩市綜合表現;00636則是追蹤富時中國A50指數,成分股涵蓋布局各產業龍頭,鎖定大市值企業,是最具代表性的A股。國泰投信分析,儘管中國近期公布七月一系列總體經濟數據,多數數據表現疲軟,零售銷售年增率由4.7%降至3.7%,遠低於市場預期,顯示先前的消費品舊換新政策效果有逐漸遞減;7月CPI年增率由0.1%降至0%,主要受到食品價格滑落而拖累,雞蛋和豬肉供給過剩加上基期過高所致,但市場普遍預期中國政府將會適時加大刺激力道,給予陸股市場正面消息。

邊緣AI開戰1/研華股價逆襲!71歲老董手機有GPT+DS+Grok「只有做這個」才能賺到錢
對剛過42周年慶的研華(2395)來說,2025年是一個關鍵轉折點。這家稱霸全球的工業電腦大廠,去年交出一張「雙降」成績單,營收597.86億元年減7%,稅後純益90.05億元下滑近17%,有趣的是,研華股價從去年11月間不到300元的谷底,翻轉上揚走出432元歷史天價,截至記者發稿股價來到394元,成功逆襲的原因只有一個,就是71歲老董劉克振口中的「邊緣AI」。「AI的普及速度實在太快了,我每天晚上看電視,沒聽到AI就睡不著啊!」劉克振在3月5日研華法說會上,幽默地開場;事實上,三個月前他才在自家「願景啟航年會」上預測,「未來十年將是邊緣AI的黃金時期」,沒想到,這波浪潮來得比預期還要快。「過去兩個月,AI的變化就是翻天覆地了。」劉克振興奮地說,過年期間中國AI新創公司Deepseek推出小模型Deepseek-R1,接著馬斯克的Grok問世、OpenAI 也陸續升級ChatGPT ,「每一兩個月都有橫空出世,未來會越來越快,到之後人家可能不理你了,因為太多了。」「我手機上就有這3個(GhatGPT、Deepseep、Grok),碰到問題就問它們,回答都差不多。」他認為,大語言模型的獲利不容易,「Deepseek沒收錢,ChatGPT我用了半天,一個月交20塊美金(約新台幣661元),有夠便宜,這樣就賺不了多少錢。」劉克振分析,AI因生成式大語言模型(LLM)的演進與普及,從高門檻技術,邁向「開源化」與「低成本」的中小型語言模型,DeepSeek的橫空出世,更讓他篤定邊緣AI時代即將全面爆發。在劉克振看來,企業不可能把所有數據都丟到雲端,這樣不僅成本高昂,還有數據安全與運算效率的問題,比如工廠、零售、醫療等場域,所以最好的解法就是在地端建立運算能力,讓AI直接進入企業的內部場景,「你服務醫院,服務工廠,那是一個一個就是真金白銀的收錢。」而這,就是劉克振口中「研華最大的機會」。研華的邊緣運算平台持續創新開發Edge AI加速模組、Edge AI產業應用系統、Edge AI大型語言訓練系統及Edge AI伺服器等產品。(圖/翻攝自研華科技臉書)工研院產業科技國際策略發展所研究經理周駿呈對CTWANT記者解釋,「通用大型模型(LLM)訓練參數高達500億(50B)以上,伴隨著高昂的資源需求和運行成本,而小型專用模型(SLM)訓練參數小於100億(10B),利用特定資料重新訓練,在專業應用、低延遲、使用者高度互動等特定應用需求上表現良好,具經濟效應與實用性,也兼具資料隱私保護要求,對LLM來說,SLM都是開源、不上雲的,特別適用於手機、物聯網、邊緣設備的應用場景。」他以製造業為例,將邊緣AI安裝於工廠設備,可即時監測機台運作狀況,檢測異常或預測維護需求,安裝於醫療業上,則可即時分析病患的生理數據(比如心電圖或血壓變化),「邊緣AI可減少資料傳輸損耗並提升反應速度,還有助於保障資料隱私。」「AI 走向百工百業的時間點,就在今年下半年!」企業導入的速度越來越快,劉克振給了自己一個「火速任務」,一錘定音,「研華基本放棄雲端市場!」全面搶入地端市場:AI邊緣運算。他的戰略很簡單:應用市場、硬體、軟體,三合一。首先,研華目前設60個事業單位(BU),深入全球不同應用市場,「未來可能會成長到100個,就是為了應對不同行業的需求。」他透露,研華為提供客製化的地端AI解決方案,將重點鎖定智慧設備、智慧交通、能源與節能、智慧醫療、智慧城市與零售等五大市場。硬體部分更是研華的「老本行」。劉克振提到,「我們累積40年經驗,擁有超過1000種產品,涵蓋工業電腦、伺服器、邊緣設備等,未來將持續優化這些產品,以支援AI運算需求。」至於軟體部分,研華正在補強,「10年前,我們才開始踏入軟體,這對研華來說是全新的挑戰。」劉克振說,為擴大開發規模,除了現有300名軟體工程師,未來計劃外包給印度公司。研華為提供客製化的地端AI解決方案,將重點鎖定智慧設備、智慧交通、能源與節能、智慧醫療、智慧城市與零售等五大市場。(圖/CTWANT資料照)研華自2016年起推出WISE工業物聯網雲平台,目前提供客戶 WISE-IoT 與 EdgeSync 兩大軟體層,劉克振說明,WISE-IoT就是提供「應用領域的集成工具,讓系統整合商能夠直接兜起來就好,不需要從零開始寫程式」。而EdgeSync就是「負責硬體與軟體的嫁接」,讓不同系統和設備「講同一種語言」,劉克振鮮活的形容,「這一塊和NVIDIA的CUDA類似,就像你煮一餐飯呢,你就買一些現成的食材炒一炒就可以。」他強調,CUDA的成功,就是因為讓所有開發者可以直接使用NVIDIA的硬體,研華要做的,就是讓客戶的應用軟體能夠無縫銜接自家邊緣運算設備。邊緣運算市場商機何時爆發?研調機構 Gartner預估,將從2023年的 131億美元到 2033 年翻 4倍到511億美元。事實上,研華已開始吃到餅, Edge AI 營收佔比已從2023年的 4%(按2023年總營收645.68億元來算,約19億元),去年提升至 9%(按2024年總營收597.86億元來算,約53億元),「今年預計達到 15%,明年希望衝破 20%。」財務長陳清熙在3月5日的法說會上這樣說,這商機正是帶飛研華股價半年上漲約兩成的關鍵。今年「台北國際電腦展(Computex)」,劉克振將帶隊重返展場,同時發表全新品牌概念「Edge Computing & WISE-Edge in Action」,宣講邊緣運算如何協同軟硬體與產業應用,「讓市場理解,地端運算將成為AI落地的關鍵技術。」在這場地端AI的競賽,劉克振已起跑。

DeepSeek有勁敵? 騰訊推AI模型T1 大摩「這2原因」上調目標價
中國網路公司騰訊21日發表深度思考模型——混元 T1 正式版,為騰訊自研的強推理模型,輸入字元價格與同業差距不大,但輸出價格為DeepSeek-R1標準時段的四分之一,顯然衝著DeepSeek而來,實際生成效果顯著優於DeepSeek-R1。混元 T1 的前身是今年 2 月中旬在騰訊元寶 APP上線的混元 T1-Preview 推理模型,該模型以騰訊於3月初發布的「混元Turbo S」為基礎打造,是一款能秒回、擅長超長文章處理的強推理模型。目前,T1 已在騰訊雲官網上線,輸入價格為每百萬字元(tokens)1 元,輸出價格為每百萬 tokens 4 元,相較於 DeepSeek 標準時段的 1/4,具有明顯的價格優勢。使用者可透過體驗位址和 Hugging Face、GitHub 等平台取得此模式的更多資訊。在CEval、AIME、Zebra Logic等中英文知識及競賽級數學、邏輯推理的公開基準測試中,混元T1的成績也達到業界領先推理模型的水準。騰訊也自信地宣布,T1的性能已達到超一流水平,僅次於OpenAI 的o1。受惠於人工智慧(AI)投資帶來的回報,加上可持續廣告收入成長、企業客戶需求及消費者市場客戶端應用變現,並致力於資本回報和利潤率提升等。摩根士丹利上調其目標價,由550港元上調14.5%至630港元,並重申「買入」評級。

輝達財報利多無效?27日跌出3兆美元俱樂部 彭博揭「這原因」
輝達財報利多無效,外加美國總統川普關稅威脅再起,輝達週四開盤後一路狂瀉 8.48%,收盤市值跌破3兆美元大關。不過,輝達仍是美國市值第二高的企業,僅次於蘋果,領先微軟。對此美媒彭博評價卻平平,認為季度業績表現好,但並不亮眼。輝達公布2024年第四季財報,營收達393.3億美元,較上季增長12%,較去年同期增長78%,第四季調整後每股盈餘(EPS)為0.89美元,優於預期的0.84美元,2025財年全年收入為1305億美元,較去年增長114%,調整後每股盈餘為2.94美元,較去年增長147%。輝達CEO黃仁勳在財報電話會上表示,DeepSeek-R1點燃了全球的熱情,公司對AI推理帶來的潛在需求感到興奮。不過,彭博社等外媒指出,輝達對其備受期待的Blackwell產品看法樂觀,這令投資者吞下定心丸,此次表現優秀,但稱不上卓越。具體來看,輝達銷售額超預期的幅度是自2023年2月以來最小的,意味著其迅猛勢頭轉弱。同時,輝達的盈利上漲幅度也是2022年11月以來最小紀錄,此外,毛利率為73%,較上季下降3個百分點。路透也引述投資研究公司D.A. Davidson分析師路里亞(Gil Luria)的看法稱,「輝達公布的營收強勁,但毛利率令人失望」。輝達周四股價一路狂瀉,以每股120.15美元作收,單日市值蒸發2730億美元,降至2.49兆美元,其股價目前已較1月6日歷史高點下跌近20%。

病人問DeepSeek後「質疑治療方法」 醫師認錯:感覺離失業不遠了
中國大陸人工智慧(AI)以及大型語言模型公司「杭州深度求索」(DeepSeek)1月20日發布並開源了DeepSeek-R1模型,該模型在數學、代碼、自然語言推理等任務上,效能媲美OpenAI o1正式版,但每百萬個token的查詢成本卻比前者便宜了98%,消息曝光後也讓美國科技權重股集體崩跌,輝達股價更暴跌16.9%。如今,更有大陸廣東的醫學博主「孤芳自賞」聲稱,病人透過DeepSeek質疑他的治療方法,而且更令人震驚的是,AI的診斷結果竟然是對的。根據《上游新聞》的報導,記者發現,評論區不少擔任醫護人員的網友都表示遭遇過類似情況,一名自稱是醫師的網友「會隱身的大娃」便回覆稱:「昨天出門診,給患者解釋完了。他給我看DeepSeek查的結果,和我說的一樣,患者誇我專業負責。」他也調侃自己:「感覺離失業不遠了。」23日,記者也聯繫了醫學博主「孤芳自賞」,對方聲稱:「患者用DeepSeek查過後,就相關治療方案有點疑問,於是就和我諮詢了一下。」他也坦承,最終DeepSeek給出的診斷結果是正確的,「我們地方醫院有些藥是沒有的,就用了替換藥,為此已經和患者解釋清楚了。」記者調查後發現,在社群平台上,還有一些醫師部落客也PO出了和博主「孤芳自賞」相似的遭遇。2月16日,部落客「幻空」發文稱,上班時遇到病人拿出DeepSeek的診斷方案,直接找他開藥。於是記者23日也連絡上「幻空」。據悉,他是深圳某醫院的孫姓醫師,他透露自己16日當天在門診看診時,突然有感染灰指甲的病人拿著DeepSeek給的處方建議要求開藥。孫醫師表示,單純就治療灰指甲來說,DeepSeek給的建議是可靠的,但關鍵還是在診斷。孫醫師也表示,他那天給病人開完藥後,晚上回家就問了DeepSeek,遇到病人帶著DeepSeek的建議,要求直接開藥該怎麼辦。結果DeepSeek回應:「作為全科醫生,面對患者攜帶非醫療機構(如Deepseek)推薦的藥物來就診的情況,應遵循以下步驟確保患者安全和醫療合規性」,接著就洋洋灑灑貼出7點建議。對此,孫醫師看完後也認為, 「Deepseek說得還算合理,最主要就是要和病人溝通,告知用藥風險。」近日,大陸湖南省醫療保障局發布《關於進一步加強基本醫療保障定點零售藥店管理的通知》,其中明確規定互聯網醫院嚴禁使用人工智能等自動生成處方,包括「醫師接診前需進行實名認證,確保由本人提供診療服務。其他人員、人工智能軟件等不得冒用、替代醫師本人提供禁診服務。」北京一家三甲醫院心臟內科的醫生也告訴《紅星新聞》,醫院醫生開處方的時候是不會使用人工智慧來進行輔助的,而購藥平台在銷售處方藥的時候,線上醫師會開立電子處方。據其了解,這些也是由值班醫師在線開立的,不會出現使用人工智慧的情況,因為醫生要對自己所開的處方負責。該醫師也補充,規定「嚴禁使用人工智慧等自動生成處方」是制度上的進一步明確,「畢竟現在人工智慧的應用比較多,很多醫院也在使用人工智慧輔助醫生的工作。但是像開處方、決定治療方案這種事情,還是需要由人來決定。」然而,《紅星新聞》注意到,近日有多家醫院或醫療機構表示,已經開始應用DeepSeek等人工智慧工具。雖然院方強調,AI工具只是輔助手段和重要幫手,在醫療過程中做出最終決定的還是醫師,但有不少實名認證的醫師近期發布了使用DeepSeek查詢治療方案的評測影片,其中多數人給出了使用DeepSeek來輔助看病,會比較「準確」和「全面」的評測結果。但專家也表示,AI短時間內還是無法取代醫師,因為AI是沒有處方權的,無論是根據法律法規,還是國家、地方的相關規定,人工智慧工具肯定是不能給病人開藥的,而且若真的按照AI的建議去開藥,出現問題的話,人工智慧也無法對病人負責,「因此這個先例是絕對不可能開的。」不過他也坦承人工智慧如果合理運用,能夠成為醫師強大的助手,「今年之前,我們醫院就已經開始使用人工智能軟體來幫助醫師診斷了,這些工具可以幫助醫師發現容易被誤診的病灶,並進行標記和提示,從而降低誤診率。」

黃仁勳首度回應DeepSeek:輝達股價暴跌是投資人誤解
NVIDIA CEO黃仁勳在日前發布的線上活動中表示,投資者對DeepSeek的誤解導致NVIDIA股價暴跌,但實際上,DeepSeek對NVIDIA而言是一個利多。1月27日上午,DeepSeek應用登頂蘋果中國地區和美國地區應用商店免費APP下載排行榜,在美區下載榜上超越了ChatGPT。據悉,DeepSeek為中國浙江省杭州市的對沖基金、量化基金和人工智慧公司,1月20日,該公司正式發表推理大模型DeepSeek-R1。推出後不久,R1就憑藉其開源的性質、大幅下降的售價和訓練成本獲得了廣泛關注。作為開源模型,R1在數學、程式碼、自然語言推理等任務上的表現能夠比肩OpenAI o1模型正式版,並採用MIT授權協議,支援免費商用、任意修改和衍生開發等。更令市場驚訝的是,根據DeepSeek介紹,R1的預訓練費用只有557.6萬美元,在2048塊輝達H800 GPU(針對中國市場的低配版GPU)集群上運行55天完成,且該模型每百萬個token的查詢成本僅為0.14美元,而OpenAI的成本為7.50美元,便宜了98%,甚至允許開源。消息曝光,也讓美國科技權重股集體崩跌,輝達股價更暴跌16.9%,觸及10月以來的新低,市值蒸發逾5000億美元(約合新台幣16兆元)。黃仁勳本人的淨資產也一度縮水近20%,不過NVIDIA的股價隨後已收復了大部分失土。對此,黃仁勳表示,市場的劇烈反應源於投資者的誤解,他強調,儘管DeepSeek的模型在推理階段表現出色,但訓練才「是智能的核心」,這是AI學習解決問題的地方。因此AI行業對NVIDIA晶片所提供的計算能力的需求實際上會增加。黃仁勳也提到,DeepSeek的創新為人工智慧領域注入了新的活力,他稱R1開源後在全球引發的熱烈反響「令人難以置信」。

輝達:DeepSeek-R1是最先進推理開放模型 可在NVIDIA NIM使用
輝達官網於美東時間30日指出,DeepSeek-R1是一個具有最先進推理能力的開放模型,且DeepSeek R1 671b已作為英偉達NIM微服務預覽版在build.nvidia.com上發布。DeepSeek R1 NIM微服務在單一輝達HGX H200系統上每秒最多可處理3872個token。開發人員可以對API進行測試和實驗,預計該API不久將作為輝達AI Enterprise軟體平台的一部分,以可下載的NIM微服務形式推出。輝達官網指出,DeepSeek-R1等推理模型不會提供直接回應,而是對查詢進行多次推理,採用思路鏈、共識和搜尋方法來產生最佳答案。執行這一系列推理過程(使用推理得出最佳答案)稱為測驗時間擴展。 DeepSeek-R1是此擴展定律的完美範例,證明了加速計算對於代理AI推理的需求至關重要。由於模型可以反覆思考問題,因此它們會創建更多輸出標記和更長的生成週期,模型品質會不斷提高。大量的測試時計算對於實現即時推理和來自DeepSeek-R1等推理模型的更高品質反應至關重要,這需要更大規模的推理部署。R1在需要邏輯推理、推理、數學、編碼和語言理解的任務中提供了領先的準確性,同時也提供了高推理效率。輝達續稱,為了幫助開發人員安全地試驗這些功能並建立自己的專用代理,6710億參數的DeepSeek-R1模型現已作為NVIDIA NIM微服務預覽版在build.nvidia.com上提供。DeepSeek-R1 NIM微服務可在單一NVIDIA HGX H200系統上每秒提供多達3872個代幣。開發人員可以使用應用程式介面(API)進行測試和試驗,預計很快就會作為可下載的NIM微服務提供,是NVIDIA AI Enterprise軟體平台的一部分。DeepSeek-R1 NIM微服務透過支援產業標準API簡化了部署。企業可以透過在其首選的加速運算基礎架構上運行NIM微服務來最大限度地提高安全性和資料隱私。透過使用NVIDIA AI Foundry和NVIDIA NeMo軟體,企業還可以為專門的AI代理程式創建客製化的DeepSeek-R1 NIM微服務。

美科技股財報周都被問DeepSeek 大佬說法一次看
中國大陸新創公司DeepSeek號稱以低價完成的AI模型,引發市場轟動,讓美股那斯達克指數周一瞬間蒸發近1兆美元的市值,剛好近期是美國科技股財報周,各家科技大老都被分析師或記者們詢問對此看法。荷蘭半導體設備巨擘艾司摩爾ASML最先公布業績,受惠於AI浪潮,去年第4季訂單遠超預期,達70.88億歐元,較第3季成長169%,全年營收283億歐元,淨利為76億歐元;預估2025年營收會在300億到350億歐元,毛利率51到53%之間。ASML執行長Christophe Fouquet在接受CNBC採訪時表示,像DeepSeek這樣的低成本AI模型,可能帶來更多應用,隨着時間推進,對晶片的需求會增加,所以我們將此視爲晶片需求增加的機會。他認為,目前超大規模雲端計算公司仍在大舉投資研發,且他們會繼續這樣做,ASML尚未聽到客戶詢問中國公司模型對晶片需求的影響;要AI在未來幾年真正發揮作用,重點還是要解決成本和能耗這兩大問題。微軟也在29日公布財報,上一季公司收入696.3億美元,年成長12.3%,略高於市場預期,但增速創2023年年中以來新低。微軟財務總監Amy Hood預計,2025財年Q3營收將在677億至687億美元之間,低於華爾街預期,財測發布後,股價在盤後交易中一度下跌5%。微軟表示,會在AI領域持續加碼,公司再向OpenAI投資7.5億美元,總投資額近140億美元,其GitHub平臺將支持Anthropic和谷歌的AI模型,OpenAI即將推出更多產品。微軟執行長Satya Nadella在業績電話會議表示,DeepSeek有一些真的創新,AI成本下降是大趨勢,DeepSeek-R1模型已可通過微軟的AI平台Azure AI Foundry和GitHub獲取,將很快在微軟AI電腦Copilot+ PC上運行。臉書母公司Meta表示,2025年資本投資將有600億至650億美元推動AI策略,去年第四季Meta旗下的臉書、IG、Messenger、WhatsApp等每日活躍用戶年增5%、至33.5億,高於預期。在業績電話會議上,Meta執行長Mark Zuckerberg表示,公司非常重視AI投資,長期投資甚至可能達到數千億美元,是Meta的戰略優勢,Meta將DeepSeek視爲新的競爭對手並正在學習,但現在判斷晶片需求是否會停止成長為時尚早,因爲晶片對推理仍至關重要。Zuckerberg表示,Meta已經完成Llama 4迷你版的訓練,而對LLM更大版本訓練「正在取得重大進展」,目標是成為世界上最具競爭力的模型。

DeepSeek遭攻擊當機!陸官媒稱攻擊IP來自美國 360周鴻禕:願提供安全支援
中國AI新創公司「DeepSeek」20日釋出DeepSeek-R1模型正式版後,因其低廉的開發成本與直追Open AI o1的性能一夕爆紅。不過DeepSeek在28凌晨傳出遭受網路攻擊消息,導致其服務一度停擺;如今中國官媒央視發表說法,表示網路安全公司「奇安信」的網路安全專家指出,DeepSeek是遭受「暴力破解攻擊」,而這些網路攻擊的IP地址「都來自美國」。網路安全企業「360集團」的創辦人周鴻禕則在網路上公開喊話表示:「如果DeepSeek有需要,360願意提供網路安全的全力支援。」根據中國央視旗下「玉淵潭天」公眾號指出,根據中國網路安全公司「奇安信」專家表示,DeepSeek近日受到「暴力破解攻擊」,網路攻擊的IP地址都在美國。王輝表示「暴力破解攻擊」的目的,在於破解DeepSeek用戶的密碼,以此取得用戶隱私訊息。目前,DeepSeek已暫時限制來自+86(中國國碼)以外的手機號碼註冊,至於已註冊用戶可以正常登錄。而中國主營安全相關的網際網路公司「360集團」創辦人周鴻禕28日在網路上公開喊話,表示「如果DeepSeek有需要,360願意提供網路安全的全力支援。」同日,周鴻禕手下「奇虎360」又高調在網路發布《關於全力支持國產大模型DeepSeek的倡議書》,宣稱360集團「作為國內最大的網路安全公司,360集團鄭重承諾將以民族大義為己任,全力以赴為DeepSeek提供全方位網路安全防護,堅決捍衛國產AI技術的尊嚴與安全!」搶搭DeepSeek順風車的意味十分濃厚。周鴻禕還趕忙在28日拍攝影片上傳,宣稱這次DeepSeek發動的大規模網路攻擊「唯獨跳過了360集團的專線機房」,又高調放話:「能夠攻破360伺服器的駭客組織還沒出生,不服氣歡迎來挑戰。」

DeepSeek重創美股「害輝達暴跌17%」 顛覆市場原因曝光
中國人工智慧(AI)新創公司深度求索(DeepSeek)於1月27日正式推出兩款全新AI語言模型DeepSeek-R1-Zero與DeepSeek-R1,並宣布以開源形式向全球開發者開放。該公司強調,這些模型在某些基準測試中的表現可與OpenAI的o1正式版匹敵,且成本僅為o1的幾十分之一。DeepSeek採用獨特的「模擬推理」(simulated reasoning)技術,運用長鏈推理(Chain-of-Thought,CoT)來拆解複雜問題,進行多步驟邏輯推理,特別適用於數學、物理和自然科學領域。儘管該技術運行時間較長,卻能顯著提升準確性。DeepSeek的技術突破引發市場震撼,顛覆了「高效AI模型需仰賴昂貴晶片與巨額資金投入」的主流觀點,導致美國科技股大幅下挫。1月27日輝達(Nvidia)股價暴跌17%,創下美股上市公司單日最大跌幅。那斯達克綜合指數(Nasdaq Composite)下跌3.1%,標普500指數(S&P 500)下跌1.5%。同日甲骨文(Oracle)重挫14%,美超微(Super Micro Computer)下跌13%,博通(Broadcom)下跌17%。根據道瓊斯市場數據(Dow Jones Market Data),此次市場暴跌導致美股蒸發約1兆美元。分析認為,投資人原先押注於新政府的親商政策與AI產業紅利,未料DeepSeek的低成本AI技術引發恐慌,顛覆市場預期。DeepSeek由中國對沖基金幻方量化(High-Flyer)創辦,致力於打造可媲美OpenAI ChatGPT與Google Gemini的AI技術。該公司透過高薪與參與尖端研究的機會,吸引中國頂尖AI人才。2023年12月DeepSeek已推出DeepSeek-V3語言模型,表現與美國主要AI產品相當。然而DeepSeek工程師透露,他們僅使用約2000片輝達晶片完成AI訓練,遠低於業界動輒1.6萬片的水準。此外,DeepSeek宣稱僅以約560萬美元完成AI系統訓練,成本遠低於Meta等美企。此舉引發業界反思,AI發展是否真的需要巨額資金投入,亦或AI產業是否存在泡沫化的風險。DeepSeek的技術策略在業界引發熱議。其方法為將數據分析任務拆解,由不同模型分工處理各自領域,使數據處理更高效,且大幅降低運算需求。卡內基美隆大學(CMU)電腦科學教授Tim Dettmers表示,DeepSeek的方法「人人皆可效仿」,顯示高效AI系統的訓練門檻已逐漸降低。然而市場對DeepSeek的低成本說法仍存疑。研究機構伯恩斯坦(Bernstein)分析師Stacy Rasgon質疑DeepSeek是否真的能以500萬美元打造出媲美OpenAI的模型;花旗(Citi)分析師Atif Malik則認為,DeepSeek在未使用先進GPU優化的情況下仍能達成高效能,令人懷疑。DeepSeek的突破對美國政府帶來新的挑戰。美國財經媒體CNBC指出,與其他中國AI模型類似,DeepSeek在面對中國政治敏感話題時有一定侷限性。此外,拜登政府過去已限制向中國出口高端AI晶片,以維持美國在全球AI競賽的領先地位。DeepSeek的成功引發外界質疑,這些限制是否反而促使中國研發人員尋求創新方法。部分專家認為,美國對中國AI發展的遏制措施仍具長期效果。然而,隨著DeepSeek展示低成本、高效能的可能性,川普政府可能進一步收緊對中國的AI技術出口管制,甚至考慮禁止銷售降規版的輝達H20晶片。美國國會已有議員呼籲採取更嚴格的措施,防止中國AI技術取得更大突破。

DeepSeek來勢洶洶! ChatGPT執行長阿特曼說話了
中國AI新創公司「DeepSeek」20日釋出DeepSeek-R1模型正式版後,因其低廉的開發成本與直追Open AI o1的性能,一夕之間成為AI界熱門話題。週二(28日)OpenAI執行長阿特曼(Sam Altman)發文肯定DeepSeek-R1模型和它的成本效益「表現出色」,但他也強調OpenAI將繼續執行既定的研究計劃,因為他認為在新的時代裡「更強大的運算比以往任何時候都重要。」阿特曼28日在推特(後更名X)上發文表示,DeepSeek-R1的表現確實出色,尤其能以極低的價格提供服務,更是令人「印象深刻」。但他同時強調,OpenAI將推出更強大的新產品以維持技術領先,並歡迎新競爭者的加入:「新的競爭對手讓人振奮,而我們將帶來更多更新與發表!」阿特曼還指出,未來OpenAI的團隊仍將執行既定研究計劃,並認為計算能力至關重要:「加強計算能力比以往更關鍵,這是實現使命的基礎。」阿特曼還表示,這個世界正期待著更多的AI工具被廣泛投入應用,並且將對即將到來的下一代模型感到非常驚訝。他並承諾,將持續致力於通用人工智慧(AGI)的開發,並突破現有技術極限:「期待為大家帶來AGI及更多成果。」

DeepSeek崛起象徵「中國AI超越美國?」 Meta AI首席楊立昆:你這樣想就錯了
中國AI新創公司「DeepSeek」20日釋出DeepSeek-R1模型正式版後,因其低廉的開發成本與直追OpenAI o1的性能,引起全球關注。不過,主導Meta AI研究的首席科學家、圖靈獎得主楊立昆(Yann LeCun)近日在網路上談起此事,認為DeepSeek的成功,最大意義在於「AI開源(open-source)的價值使任何人都能受益」,而非證明「中國AI技術能對其他國家帶來競爭威脅」。(圖/翻攝Threads/yannlecun)「致那些看到DeepSeek表現並且思考的人:」楊立昆在Threads寫道:「如果你看到的是『中國在AI領域超越了美國』,那麼你的解讀就錯了;正確的解讀應該是『開源模型正超越專有模型』。」DeepSeek-R1屬開源模型(open source),亦即開放程式碼任憑公眾檢閱學習,目前Meta AI的Llama也採取開源。楊立昆指出,DeepSeek受益於開放研究(Open Research)和開源,包含Facebook時期的PyTorch、Meta時期的Llama都提供了資料,正因有人提出新想法,才有其他人在這些前人打下的工作基礎上加以實現,「他們發布且開源,所以每個人都能從中受益,這就是開放研究和開源的力量!」在這則發文底下,一名匿名但自稱來自中國的AI工程師留言表示,「是的,你說得對。我們也在使用PyToch和Llama,這並不代表所謂的『超越』。這正是『開源』的靈魂,賺錢固然重要,但幫助其他人、彼此互惠,是更重要的事。世界上有太多商人與政客在我們之間劃出了界限,但在開放的世界裡,沒有什麼叫『超越』,我們可以一起努力讓世界變得更好。」OpenAI初創時是一家開源AI公司,當時他們宣稱其使命是「創造造福全人類的技術」,不過在聲名大噪後轉向閉源。馬斯克(Elon Musk)曾在2024年2月底控告OpenAI及其執行總裁山姆‧阿特曼(Sam Altman),訴訟書講述OpenAI公司成立協議,標明會尋求開放程式碼,不滿對方如今並未公開其技術。
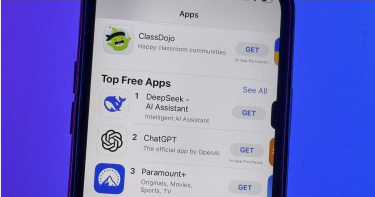
輝達股價暴跌16.9%急發聲明:證明DeepSeek需要更多H800 GPU
中國大陸人工智慧以及大型語言模型公司「杭州深度求索」(DeepSeek)20日發布並開源了DeepSeek-R1模型,該模型在數學、代碼、自然語言推理等任務上,效能媲美OpenAI o1正式版,但每百萬個token的查詢成本卻比前者便宜了98%,消息曝光後也讓美國科技權重股集體崩跌,輝達股價更暴跌16.9%。對此,輝達於美東時間27日發布聲明稱,DeepSeek的進展表明了輝達晶片對中國市場的重要性,因此未來還需要更多輝達的低階晶片來滿足DeepSeek服務的需求。據悉,DeepSeek為中國浙江省杭州市的對沖基金、量化基金和人工智慧公司,1月20日,該公司正式發表推理大模型DeepSeek-R1。該模型在數學、代碼、自然語言推理等任務上,效能媲美OpenAI o1正式版,且在27日於美國地區蘋果App Store下載榜上超越ChatGPT,並登頂App Store免費應用程式榜榜首。然而,R1的預訓練費用只有557.6萬美元,在2048塊輝達H800 GPU(針對中國市場的低配版GPU)集群上運行55天完成,且該模型每百萬個token的查詢成本僅為0.14美元,而OpenAI的成本為7.50美元,便宜了98%,甚至允許開源。消息曝光,也讓美國科技權重股集體崩跌,輝達股價更暴跌16.9%,觸及10月以來的新低,市值蒸發逾5000億美元(約合新台幣16兆元),就連輝達的競爭對手AMD股價也下跌超過6%至115.01美元。對此,輝達27日也發布聲明來緩解投資人的擔憂,輝達稱,DeepSeek的進展表明了輝達晶片對中國市場的重要性,因此未來還需要更多的輝達晶片來滿足DeepSeek服務的需求,「DeepSeek的工作說明了如何使用該技術創建新模型,並利用廣泛可用的模型和完全符合出口管制的計算能力。」據DeepSeek的1篇研究論文顯示,它使用了大約2000個Nvidia的H800晶片,這些晶片的設計目的是遵守美國2022年所發布的出口管制規定;然而專家也告訴《路透社》,這些科技出口禁令不會減緩中國的人工智慧發展。蘭德公司技術分析高級顧問古德里奇(Jimmy Goodrich)則透露,中國至少有十幾台大型超級電腦配備了大量Nvidia晶片,在DeepSeek使用這些晶片來學習如何提高效率時,這些晶片是合法購買的,而運算效率也是美國人工智慧公司關注的重點。古德里奇強調,「DeepSeek並不是憑空出現的——他們多年來一直致力於模型構建。眾所周知,DeepSeek擁有一支非常優秀的團隊,如果他們能夠獲得更多先進的計算能力,天知道他們會有多強大。」

低成本開發DeepSeek 網傳雷軍開千萬年薪挖角中國天才AI少女
中國AI初創公司DeepSeek近期推出的DeepSeek-R1模組,其以低成本與高效能震撼AI領域,不僅在Chatbot Arena基準測試中躋身全球前三,更登上蘋果中國及美國應用商店免費APP排行榜首位,與OpenAI的ChatGPT平分秋色。而在背後的關鍵人物,竟然是一位1995年後出生的少女羅福莉。根據中國媒體報導指出,杭州深度求索人工智能基礎技術研究有限公司於2023年創立DeepSeek,專注於大語言模型的開發。公司2024年底推出的DeepSeek-V3模型,以其超越主流開源模型的性能和低廉的訓練成本在業界爆紅,甚至被譽為「AI界拼多多」。根據最新發布的DeepSeek-R1,其預訓練費用僅557.6萬美元,不到OpenAI GPT-4o的十分之一,卻能實現相當的功能與表現,令矽谷的微軟、Meta、Google等巨頭高度重視。DeepSeek的API服務價格也極具競爭力,每百萬輸入tokens僅需人民幣1至4元,輸出tokens則為人民幣16元。而DeepSeek能順利誕生的關鍵人物,就是1995年後出生的羅福莉,他本科畢業於北京師範大學計算機專業,後於北京大學攻讀計算語言學碩士,在學期間便在國際AI研討會上發表8篇學術論文,可說是備受矚目。畢業後,他加入阿里達摩院,主導開發多語言預訓練模型VECO,隨後跳槽至幻方量化,專注深度學習與策略建模。2022年,她加入DeepSeek,成為DeepSeek-V2的核心開發者之一,參與研發劃時代的AI模組。據傳聞,DeepSeek-V3發布前夕,小米創始人雷軍曾開出千萬人民幣年薪力邀羅福莉加入,希望由其領導小米AI大模型團隊。但目前尚未有消息顯示羅福莉是否接受邀約。
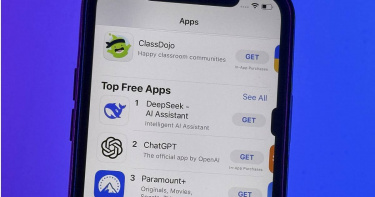
DeepSeek多次當機 官方稱「遭大規模惡意攻擊」
中國大陸人工智慧以及大型語言模型公司「杭州深度求索」(DeepSeek)20日發布並開源了DeepSeek-R1模型,該模型在數學、代碼、自然語言推理等任務上,效能超越OpenAI o1正式版,且在27日於美國地區蘋果App Store下載榜上超越ChatGPT,並登頂App Store免費應用程式榜榜首。然而,DeepSeek服務這幾天卻發生多次當機,對此DeepSeek官方也回應了。1月27日當天,DeepSeek服務多次當機。上午10點55分,發生第1次大規模當機,DeepSeek API服務不可用,DeepSeek-R1 API服務在11點32分恢復,DeepSeek-V3 API服務在14點21分恢復。而在14點37分,發生第2次大規模當機,DeepSeek網頁和API不可用,該問題在16點43分解決。晚間20點16分,DeepSeek又出現了無法登入和註冊的問題,在21點32分得到解決。而在前一天的26日,DeepSeek也當機過2次,一次在下午14時發生,一次在晚間22時發生。DeepSeek隨後回應稱,1月26日下午DeepSeek確實出現了局部服務波動,但問題在數分鐘內得到解決。此次事件原先懷疑可能與新模型發布後的訪問量激增有關。在此之前,DeepSeek的上一次故障要追溯到1月14日。DeepSeek官方27日又回應,由於近期DeepSeek線上服務受到大規模惡意攻擊,為持續提供服務,暫時限制了+86手機號以外的註冊方式,目前已註冊用戶已經可以正常登錄、使用,感謝理解和支持。1月27日上午,DeepSeek應用登頂蘋果中國地區和美國地區應用商店免費APP下載排行榜,在美區下載榜上超越了ChatGPT。據悉,DeepSeek為中國浙江省杭州市的對沖基金、量化基金和人工智慧公司,1月20日,該公司正式發表推理大模型DeepSeek-R1。推出後不久,R1就憑藉其開源的性質、大幅下降的售價和訓練成本獲得了廣泛關注。作為開源模型,R1在數學、程式碼、自然語言推理等任務上的表現能夠比肩OpenAI o1模型正式版,並採用MIT授權協議,支援免費商用、任意修改和衍生開發等。更令市場驚訝的是,根據DeepSeek介紹,R1的預訓練費用只有557.6萬美元,在2048塊輝達H800 GPU(針對中國市場的低配版GPU)集群上運行55天完成,且該模型每百萬個token的查詢成本僅為0.14美元,而OpenAI的成本為7.50美元,便宜了98%,甚至允許開源。消息曝光,也讓美國科技權重股集體崩跌,輝達股價更暴跌16.9%,觸及10月以來的新低,市值蒸發逾5000億美元(約合新台幣16兆元)。